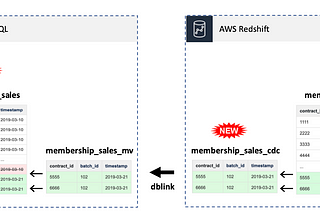
Paul SingmaninWhispering DataScaling AWS Redshift Concurrency with PostgreSQLThe most efficient way to move data between an analytics warehouse and an OLTP data store!Feb 10, 20231Feb 10, 20231
Paul SingmaninWhispering DataThe State of Data Engineering 2022All the latest tools and trends in data engineering.Jun 27, 202213Jun 27, 202213
Paul SingmaninWhispering Data5 Tips For a Tidy Data WarehouseSpark joy in your data warehouse by following these data modeling best practices!Jun 13, 2022Jun 13, 2022
Paul SingmaninWhispering DataTowards Effective DataOpsGain the confidence to mess with your data without making a mess of your data.May 6, 2022May 6, 2022
Paul SingmaninWhispering DataBuilding a Personal Data Stack to Alert on Crypto Price Fluctuations — Trying Out Hex and Delta…If you’re like me, you bought your first cryptocurrency in the past year or so, right when it stopped going up in price and making random…Mar 21, 2022Mar 21, 2022
Paul SingmaninWhispering DataLevel Up Your Data LakeTake your data lake game to new heights with these two architecture improvements.Feb 22, 2022Feb 22, 2022
Paul SingmaninWhispering DataHow Easy It Is to Re-use Old Pandas Code in Spark 3.2?In October, it was announced that the Pandas API was being integrated with Spark. This is particularly exciting news for a Pandas-baby like…Feb 7, 2022Feb 7, 2022
Paul SingmaninWhispering DataThe Everything Bagel II: Versioned Data Lake Tables with lakeFS and TrinoLet’s put the bagel to use by querying branched lakeFS data from Trino’s distributed engine.Jan 29, 2022Jan 29, 2022
Paul SingmaninWhispering DataThe Guide to Data VersioningAlready familiar with versioning code with git? A look at how it works to version data using the same abstractions.Dec 13, 20211Dec 13, 20211
Paul Singman3 Ways to Add Data to lakeFSFew people start using lakeFS without first having some data collected. Consequently, it is common that after getting it up and running…Nov 10, 2021Nov 10, 2021